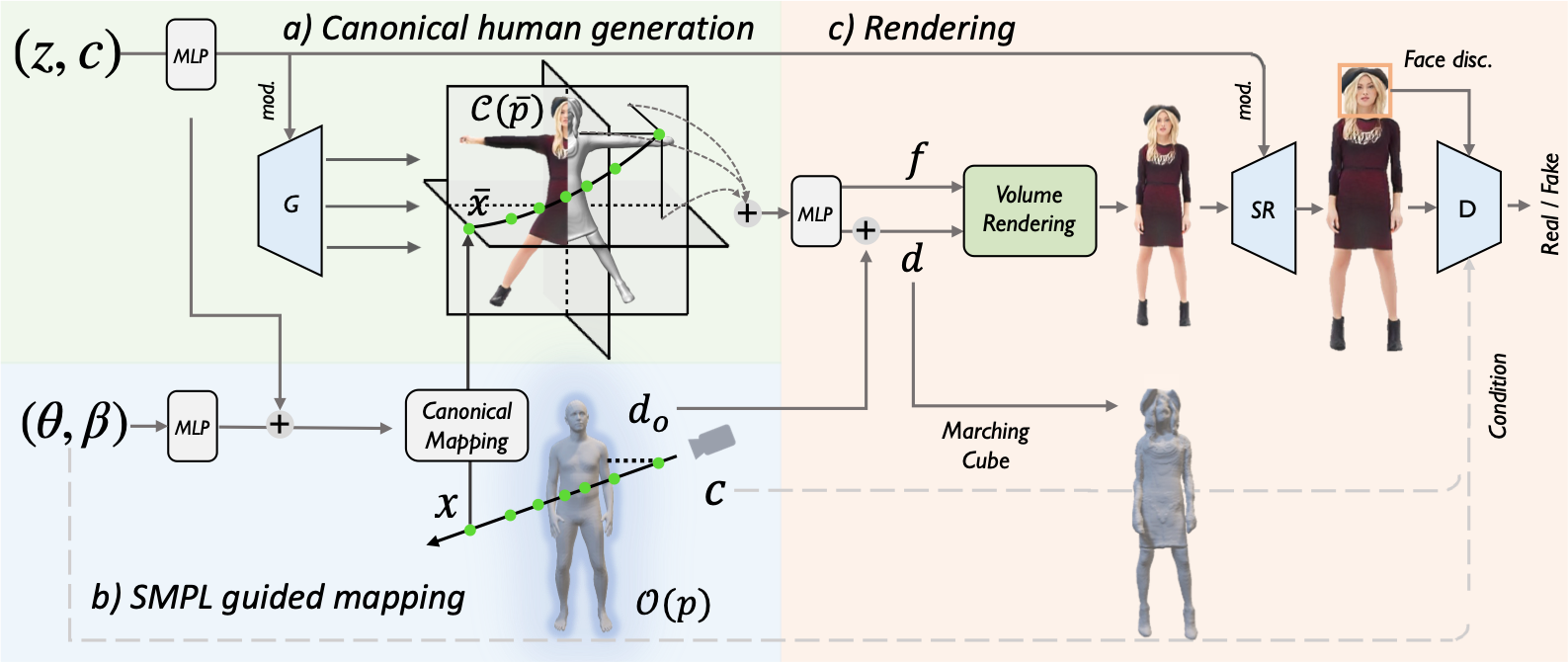
AvatarGen: A 3D Generative Model for Animatable Human
- Jianfeng Zhang*,1
- Zihang Jiang*,1
- Dingdong Yang2
- Hongyi Xu2
- Yichun Shi2
- Guoxian Song2
- Zhongcong Xu1
- Xinchao Wang1
- Jiashi Feng2

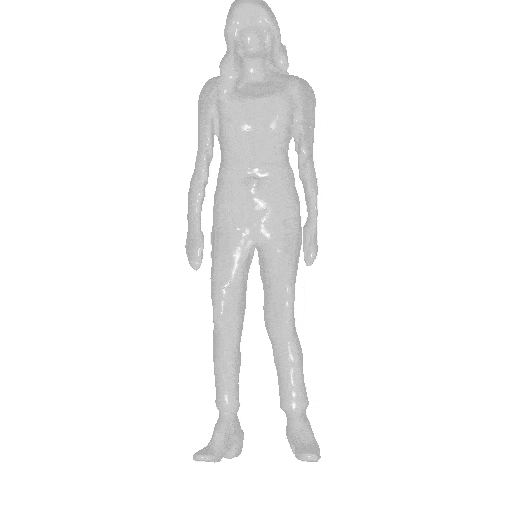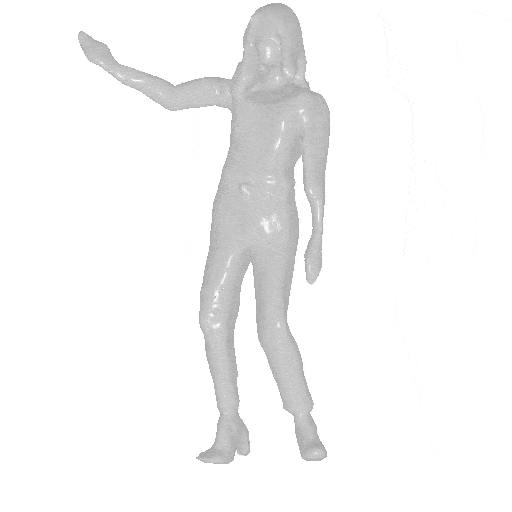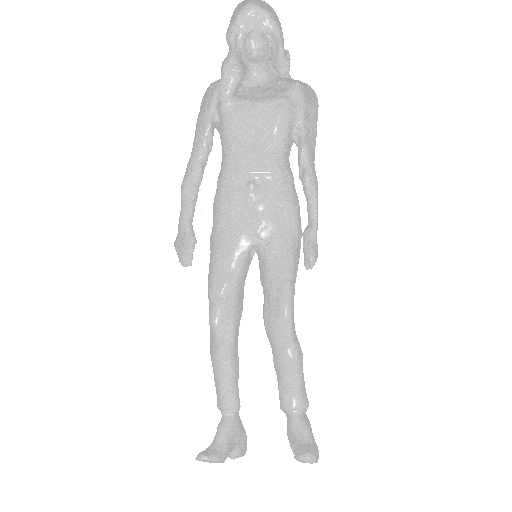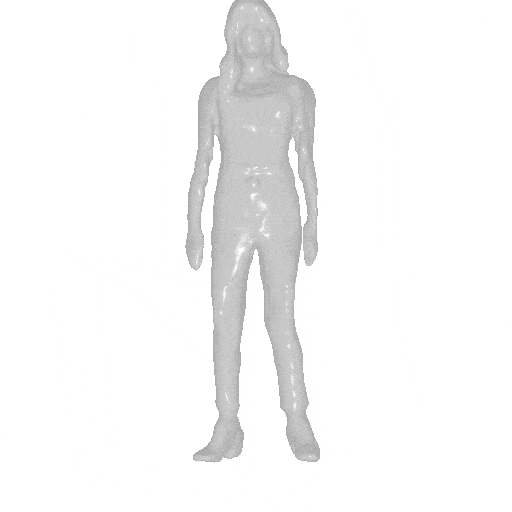
AvatarGen can synthesize 3D-aware human avatars with detailed geometries and diverse appearances under disentangled control over (a) camera viewpoints, (b) human poses and (c) shapes. (d) Moreover, given the SMPL control signals, the generated avatars can be animated accordingly.
We generate avatars via AvatarGen and render them from 360-degree viewpoints (left). The avatars can be animated given a SMPL sequence (right).



|


|


|


|


|


|


|


|


|


|


|


|


|


|


|


|

|


|


|


|

|


|


|


|


|


|


|


|


|


|
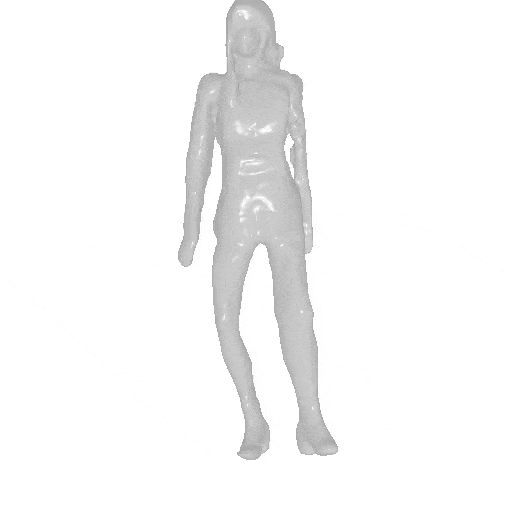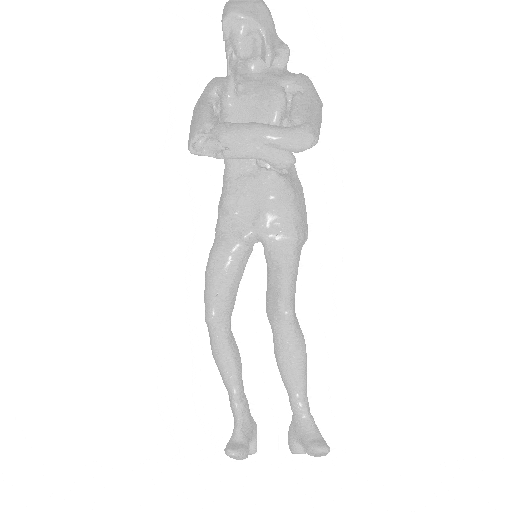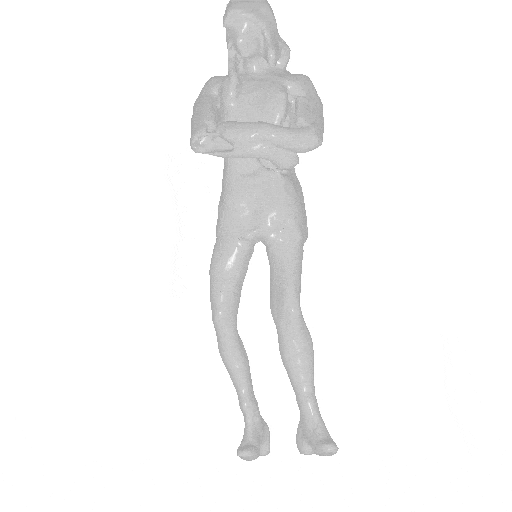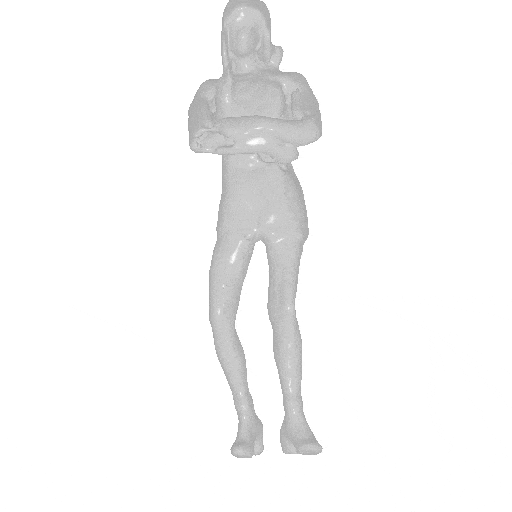
Given different SMPL sequences, AvatarGen can animate the generated avatars accordingly, while preserving their identities.
| Input and inversion | Geometry | Novel pose | Geometry |
 |
 |
 |
|
 |
 |
 |
Given a target portrait, we reconstruct its 3D-aware appearance and geometry, which can then be rendered under novel camera views and re-posed using novel SMPL parameters as control signals. Please kindly refer to Section 4.3 for more details.
| Text prompts | |||
| Light blue jeans | |||
| Long dress |
Text-guided synthesis results of AvatarGen with multi-view rendering. We optimize the latent code of the synthesized images with a sequence of text prompts that specify different cloth styles. Please kindly refer to Section 4.3 for more details.
Given an audio sequence, we use the open-source audio-to-motion method Bailando to generate the corresponding SMPL sequence, and then apply it to animate the generated avatars. We fix avatars' orientation and position for better visualization (click to play, video with audio).
@article{Avatargen2023,
title={AvatarGen: A 3D Generative Model for Animatable Human Avatars},
author={Zhang, Jianfeng and Jiang, Zihang and Yang, Dingdong and Xu, Hongyi and Shi, Yichun and Song, Guoxian and Xu, Zhongcong and Wang, Xinchao and Feng, Jiashi},
journal={ArXiv},
year={2023}
}